

Understanding Foundation Models: Paving the Way for AI Breakthroughs
Are you curious about the technology behind GPT and DALL-E and why it has been branded as revolutionary? You are in the right place because down below we explain foundation models, the groundbreaking technology that is about to change the world.
What are foundation models?
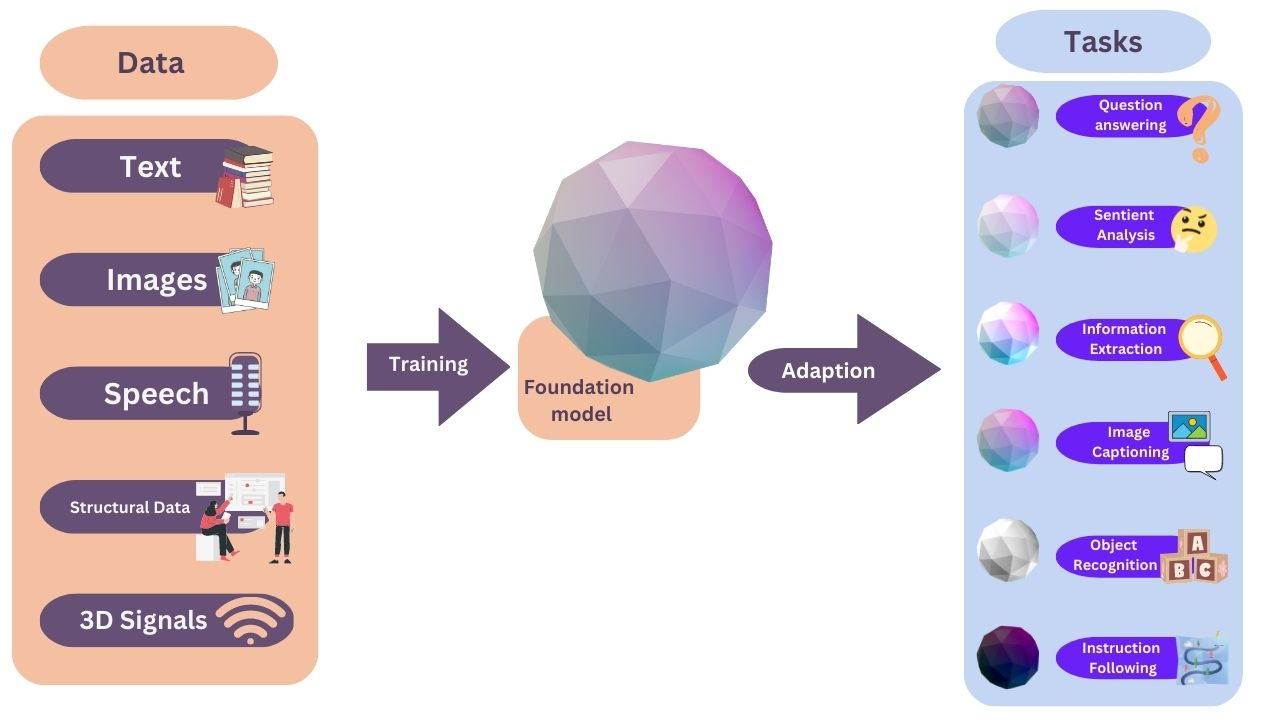
Foundation models are AI models that can be adapted to a wide range of other tasks. Foundation models are typically large-scale models (they have over billions of parameters) that are able to generate output in a form of text, image, code or other.
Foundation models are trained to give us desired outputs using a lot of information that doesn’t have labels, which means no one told the machine what it was looking at, as defined by IBM Research. IBM has been researching how to make AI’s use more broad and flexible ever since Stanford published the first paper based on their research on foundation models in 2021.
GPT, BERT, and DALL-E are all early examples of foundation models. Previously, foundation models (which are natural language processing AI models) needed a lot of labeled examples of data just for them to summarize the inputted text. So not only were large amounts of data often required for training procedures, but also tools for preprocessing, cleaning, and transforming the comprehensive data. This type of training is called supervised learning.
With the rise of foundation models, you can now input a single sentence prompt, and the system will generate an entire essay, complex image, or specific piece of code, even though the model wasn’t specifically trained to do that. This is accomplished by having the model trained on a broad data set of unlabeled data, deep neural networks, that can be used for accomplishing different tasks, with minimal fine-tuning and preprocessing. This type of training is called unsupervised learning. With unsupervised deep learning algorithms, the algorithm will discover patterns and structures within the data that would take humans much more time.
Foundation models like these will be the foundation of the numerous applications of AIs: from healthcare to finance. However, it also raises important issues, such as concerns about bias, privacy, economic and environmental impact, and job displacement, and requires careful legal and ethical considerations.
AI principles behind foundation models
The following are some of the core principles behind foundation models, which will make it easier to understand the technology behind AI.
Training data
In order to develop machine learning algorithms, we need large amounts of data, along with tools for processing, cleaning, and transforming this data into something tangible. This data, used to train machine learning algorithms, is known as training data. It can be, as discussed above, labeled (annotated with the correct output for the given input) and unlabeled (the data consists only of inputs).
Self-supervised learning
Self-supervised learning is a type of unsupervised learning that involves training a machine learning algorithm to predict some part of the input data, without using explicit labels.
Overfitting
Overfitting occurs when the foundation model is trained too well on the training data and performs poorly on new, unseen data. Overfitting can occur when the foundation model has too many parameters or when the training data for large-scale models is too small or biased.
Parameters and weights
Parameters are the values that a foundation model learns from the training data to make predictions or decisions. Weights are the values that the foundation model assigns to the parameters during training. The weights are adjusted during training to give optimal performance and minimize the error between the foundation model’s predictions and the actual outputs.
Fine-tuning and prompt engineering
Foundation models can be adapted to new tasks or domains using techniques like fine-tuning and prompt engineering.
Fine-tuning involves taking a pre-trained foundation model and then training it further on a new dataset that is related to the original dataset. This can help the foundation model perform better on the new task.
Prompt engineering involves designing prompts or questions that can be used to guide the behavior of the foundation model.
Evaluation metrics
Evaluation metrics are the metrics used to evaluate the performance of foundation models. Common evaluation language modeling metrics include accuracy, precision, recall, and F1 score.
Neural networks
Neural networks are types of foundation models that are based on the structure and way of functioning of neurons in the human brain. The networks consist of layers of interconnected nodes that process input data and make predictions or decisions. Deep learning is a type of neural network that consists of many layers and is capable of learning more complex features and patterns.
Characteristics of foundation models
Foundation models vary in type and architecture, and their features evolved since their conception. And yet, some of the key characteristics remain in all types.
Foundation models are generative in nature. They are a type of AI model that will based on a brief input generate an output (such as text, images, videos, or blocks of code).
Every foundation model is trained on broad data without labels, and will typically use self-supervision as the training method. These foundation models contain hundreds of millions to billions of parameters.
Foundation models learn generalizable and adaptable data representations that can be used for multiple downstream tasks. They can be adapted to new tasks or domains using different techniques like fine-tuning, prompt tuning, and prompt engineering.
It is important to note that foundation models may exhibit emergent behaviors not anticipated or intended during training. For example, foundation models may produce hallucinations (confident responses by AI that are not justified by its training data, which are unexpected and often surreal outputs). The term gained popularity in 2022 when the large language model ChatGPT rolled out.
Types of foundation models
Foundation models can vary based on their architecture. The architecture underwent changes during model development. Down below we listed a number of foundation models, from the first release to the most recent examples.
Generative adversarial networks (GANs)
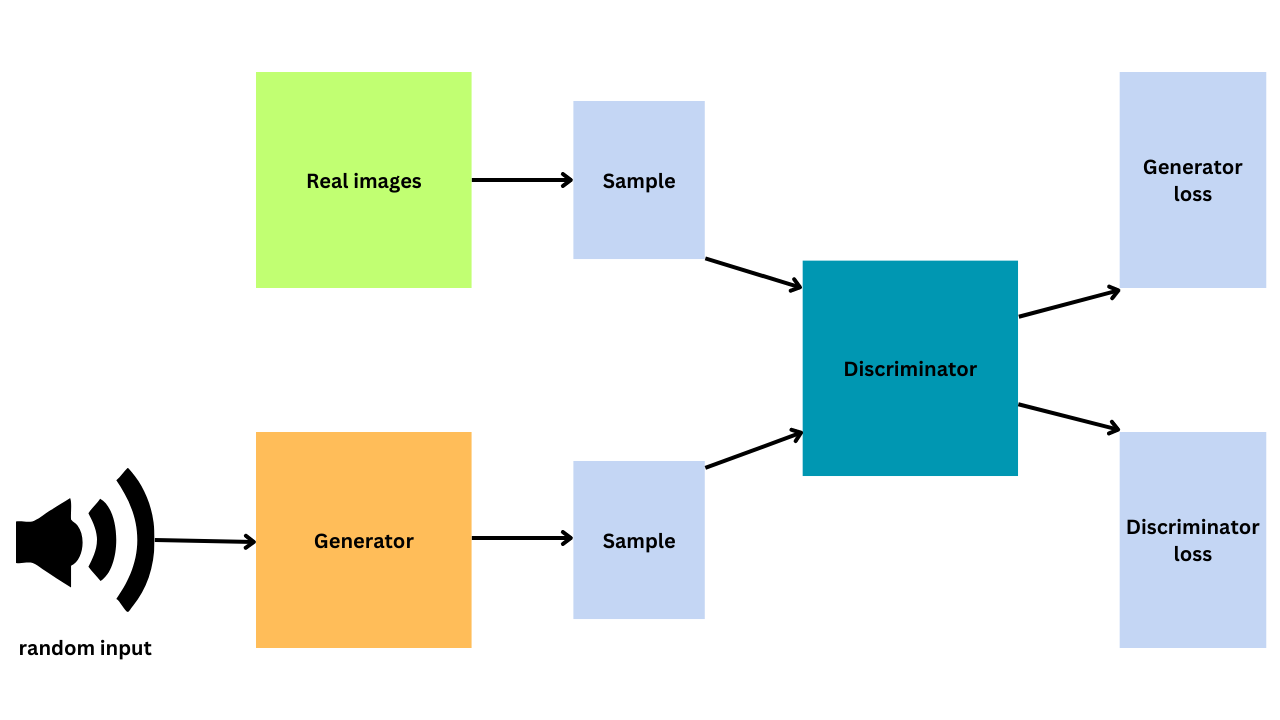
Generative Adversarial Networks (GANs) are foundation models that can generate new examples based on training data using deep learning methods, according to Brownlee from Machine Learning Mastery (2019). GANs use two sub-models: the generator and the discriminator.
The generator creates new examples, and the discriminator tries to tell if they are real or fake. After the discriminator tries to classify real and fake samples, it is updated to do a better job in the next round. The generator is also updated based on how well it fooled the discriminator. The two models compete in a game until the generator can create examples that fool the discriminator about half the time.
Examples of GANs
GANs are exciting because they can create realistic examples across many domains and types of data, including images. They can even create fake photos that look real to humans. However, GANs can also produce unexpected results, and it’s important to be aware of their limitations. Goodfellow suggests in his paper from 2017 that conditional GANs are particularly useful for generating new examples in various tasks. Some of the most compelling applications of conditional GANs include:
- Image Super-Resolution: creating high-quality images from low-quality ones. For example, making a blurry picture clearer and more detailed.
- Creating Art: using AI to make new and interesting images, like sketches or paintings.
- Image-to-Image Translation: changing a photo’s appearance in different ways. For example, turning a daytime photo into a nighttime one or making a summer photo look like it was taken in winter.
Variational auto-encoders (VAEs)
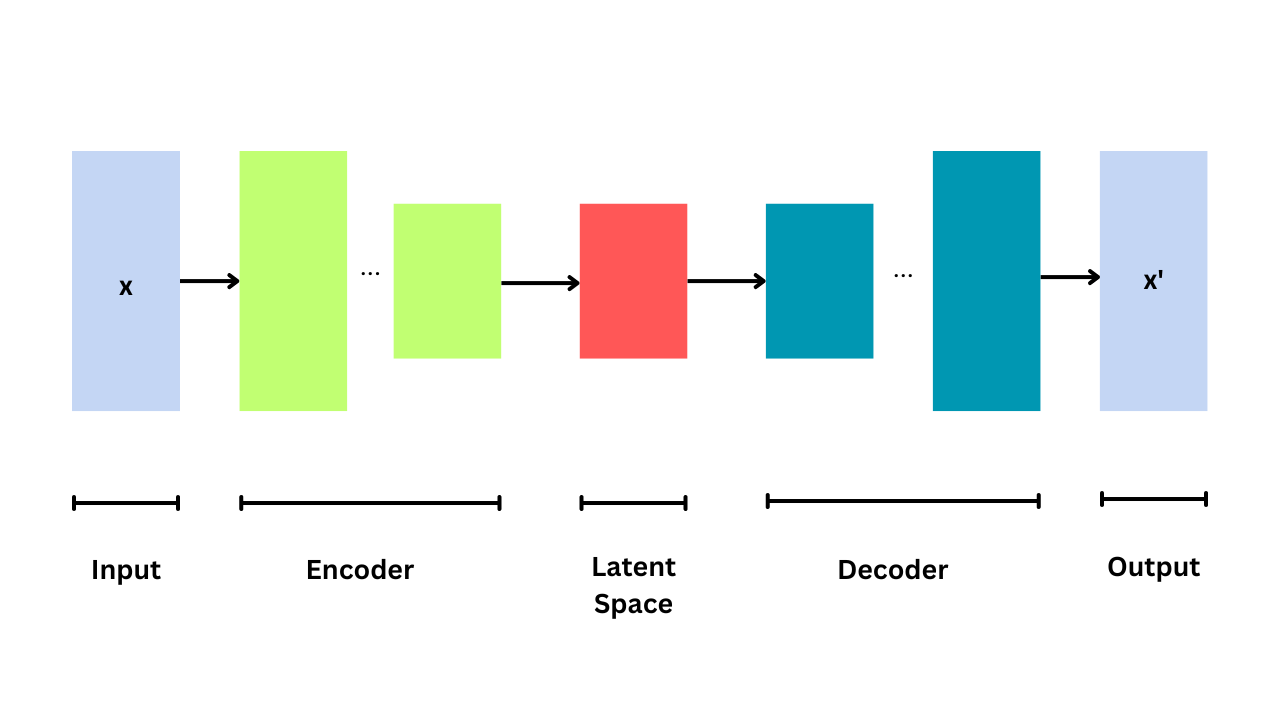
Variational auto-encoders (VAE) are the type of foundation models that can generate new data, like images or music. They work by learning the patterns in existing data and using that knowledge to create new examples. During training, the VAE ensures that the patterns it learns are useful for creating new data.
The term “variational” comes from how the VAE avoids overfitting and ensures that the patterns it learns are useful. In summary, VAEs are autoencoders whose training is regulated to avoid overfitting and ensure that the latent space has useful properties.
Examples of VAEs
VAEs have various applications, including:
- Image generation of new images of faces, animals, and other objects.
- Data compression into a smaller representation without losing too much information.
- Anomaly detection in data by comparing the reconstructed data with the original data.
Transformer-based large language models (LLMs)
Transformers are a type of neural network architecture of foundation models that can process large amounts of complex data types like text, images, videos, and audio. Transformers use a combination of positional encodings, attention, and self-attention to understand the order and relationships of words in a sequence, allowing them to process text more efficiently and effectively.
One of the key innovations of transformers is the attention mechanism, which allows the model to focus on different parts of the input text as it processes it. This mechanism allows the model to efficiently process long sequences of text and capture complex relationships between words, and output significantly more natural language.
Examples of how transformer models can be used
Examples of the use of transformers include:
- Natural Language Processing (NLP): they are used in NLP models like GPT-3, BERT, and T5 that can perform tasks like writing articles, answering questions, and generating creative writing like poetry.
- Protein Folding: helping predict the structures of proteins from their genetic sequences.
- Computer Vision: performing computer vision tasks such as image classification and object detection.
- Music Generation: generating new music based on existing songs or styles.
- Code Generation: generating code for specific programming tasks.
Popular transformer-based large-language models
GPT

GPT stands for “Generative Pre-trained Transformer” and refers to a class of large neural language models developed by OpenAI, starting in 2018. These large language models, like ChatGPT and GPT-4 we know today, use transformer-based architecture to generate human-like language and can be fine-tuned for a variety of natural language processing tasks, such as language translation, text summarization, and question-answering.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based language model developed by Google in 2018. BERT uses a bidirectional approach to train a deep neural network on large amounts of text data, allowing it to learn context and generate more accurate language predictions. It has achieved state-of-the-art results on a wide range of natural language processing (NLP) tasks, including question-answering, sentiment analysis, and language translation.
BLOOM
BLOOM is a language model capable of generating text in 46 natural languages and 13 programming languages, with 176 billion parameters. It was developed through the largest collaboration of AI researchers ever involved in a single research project and is available for download under the Responsible AI License.
The model is not only a one-and-done solution but is expected to continue to improve as the workshop experiments and tinkers with it, adding more languages and using it as a starting point for more complex model architectures.
Diffusion models
Diffusion models are types of artificial intelligence foundation models that generate new data similar to its training data. They work by gradually adding noise to an image in a very controlled manner and learning to reverse this process to generate new data. Diffusion models are very flexible and can be used for various tasks, like generating images and processing language.
Diffusion models do not require adversarial training, which is a notoriously difficult and time-consuming process. Instead, diffusion models use a simple yet effective approach to generate data.
They are essential to the performance of models like DALL-E 2. With further improvements expected in the coming years, diffusion models are the most exciting area of research in the field of AI and foundation models.
Examples of diffusion Models
Stable DIffusion
Stable diffusion is a recently proposed variant of the diffusion model that aims to improve its stability and sample quality. It does this by modifying the model training process to encourage the model to learn a more stable latent space, which in turn leads to better-quality samples. Latent space refers to an abstract space where a model stores information about the data it was trained on. In the case of diffusion Models, the latent space represents the noise added to an image.
DALL-E 2

DALL-E 2 is a large language model developed by OpenAI that uses a diffusion model to generate images from text descriptions. The model is based on a technique called contrastive learning, which involves training the model to recognize the differences between similar images and then using that knowledge – generate new images and art.
Its ability to capture the nuances of language and produce visually and aesthetically compelling output has important applications in fields like design, advertising, and content creation, making it one of the first human-centered artificial intelligence.
Bottom line
Foundation models have evolved rapidly and innovatively in recent years and we are only starting to see how fine-tuning can broaden their use in different industries. However, this revolutionary technology prompts discourse about originality, ownership, bias, privacy, and job displacement.
Despite the potential issues, foundation models have brought significant advancements to healthcare, finance, and the arts. As research on foundation models continues to evolve and foundation models continue to improve, we are going to witness the area get more regulated as AI systems continue to be applied in solving more complex problems and creating more possibilities for AI and humans alike.
Interested in trying out tools that leverage the power of foundation models? Check out our recommendations for each of these categories:




