

From Noise to Art: Understanding Diffusion Models in Machine Learning
Diffusion models have the power to generate any image that you can possibly imagine. ANY! Even a portrait of your dog in the style of the great Picasso! But their power doesn’t stop there, with generating images. As of lately, they can generate videos and help you totally change your own photos with inpainting and outpainting, with no photoshop skills required on your end.
If you want to know how they do their magic, scroll down below where we discuss some of the key principles behind AI tools like these.
What are diffusion models?
Diffusion models are a type of foundation model that can generate new data based on the data they were trained on (training data). They work by adding Gaussian noise to an image, which is essentially random pixels or distortion changes that affect the original image. This process is called the forward diffusion process. The diffusion model then learns to remove this added noise in the reverse diffusion process, gradually reducing the noise level until it produces a clear and high-quality image.
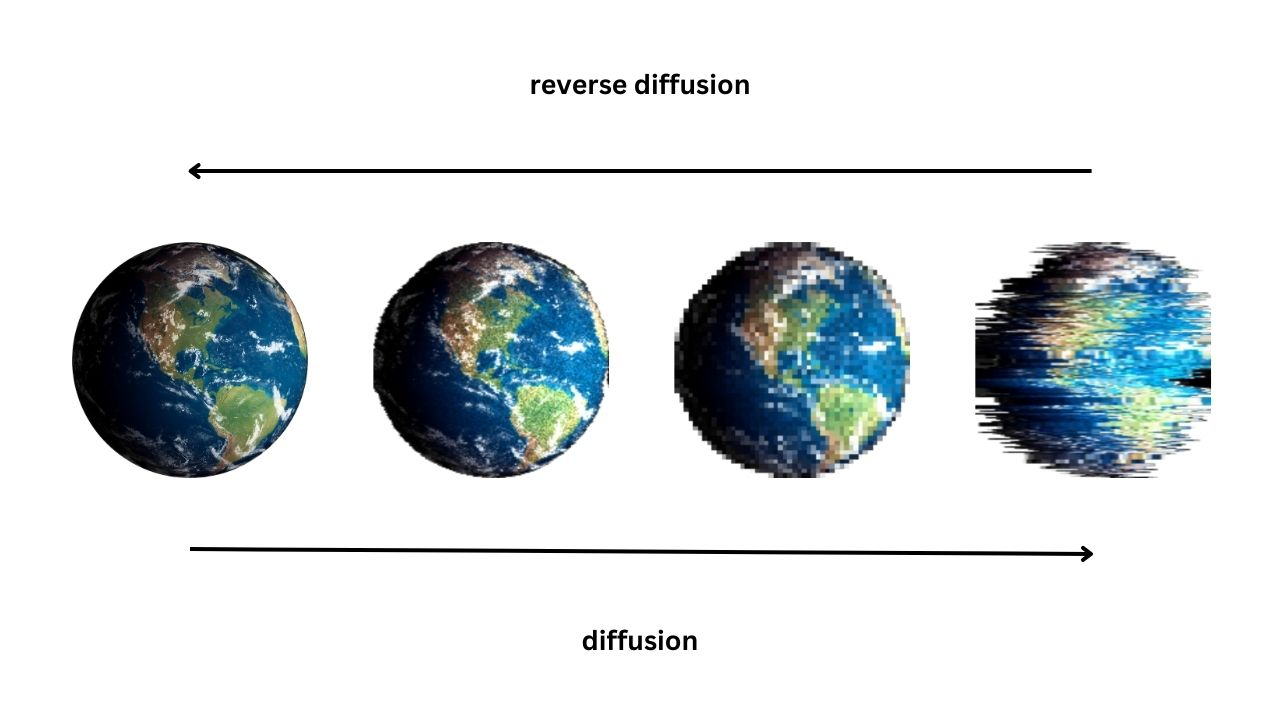
Think of it like adding a layer of static or distortion to a TV screen, and then the model learns how to remove that static to restore the original image. By doing this, diffusion models can generate new high-quality images that are similar but slightly different from the original, which results in a wide variety of possible outputs. This process helps diffusion models create more diverse and stable images than other methods and models.

If you are interested in learning more about foundation models, you can check out our article on foundation models, where we explained the technology and terminology behind these tools.
AI principles behind diffusion models
In order to better understand how diffusion models work, and how they are able to generate images based on our text input, we’ll first need to elaborate on some technical terms.
Generative modeling

Essentially, generative models are a type of AI that can learn how to create new content (generate images or text) that looks or sounds like something it has seen before from training data.
Generative models include generative adversarial networks (GANs), variational auto encoders (VAEs), transformer-based large language models (LLMs), and diffusion models. Diffusion models are a relatively new addition to the field of generative models.
Computer vision

The term refers to a field of artificial intelligence that focuses on letting computers “see” and understand images and videos in the same way that humans do. It is often used in conjunction with generative models to help the model learn to generate images or videos that look realistic and follow the rules of physics of the visual world.
Diffusion models don’t use computer vision in the same way like GANs and VAEs do. Diffusion models rely on a different technique called score-based generative modeling.
Score-based generative modeling
Score-based generative modeling is used in diffusion models to improve their performance. In this kind of modeling, the diffusion model is trained to measure how likely a new image is to be generated from existing data. This is called a score function. By training and sampling algorithms from this function, the model can generate new images that look similar to the existing data. It is considered more stable than other methods.
Latent space
Latent space is a mathematical space that represents abstract features of data. In the case of generative models, latent space is where the model learns to map existing data to new, similar data. It is a virtual space where similar images or text are grouped together by the diffusion model, as it learns, based on their shared features. This helps the diffusion model generate images that look real.
Gaussian noise

Gaussian noise is a type of random noise that is often added to the input data of a diffusion model. This is done to help the diffusion model learn to generate new data that is similar to the training data, even when the input is not perfect. The noise is generated using a Gaussian distribution, which is a type of probability distribution that describes the likelihood of different values occurring within a given range.
Adding Gaussian noise to the input data can help the model learn to recognize patterns that are robust to small variations in the input. Gaussian noise can also be used for other purposes in machine learning, like regularization or data augmentation.
Reverse diffusion process
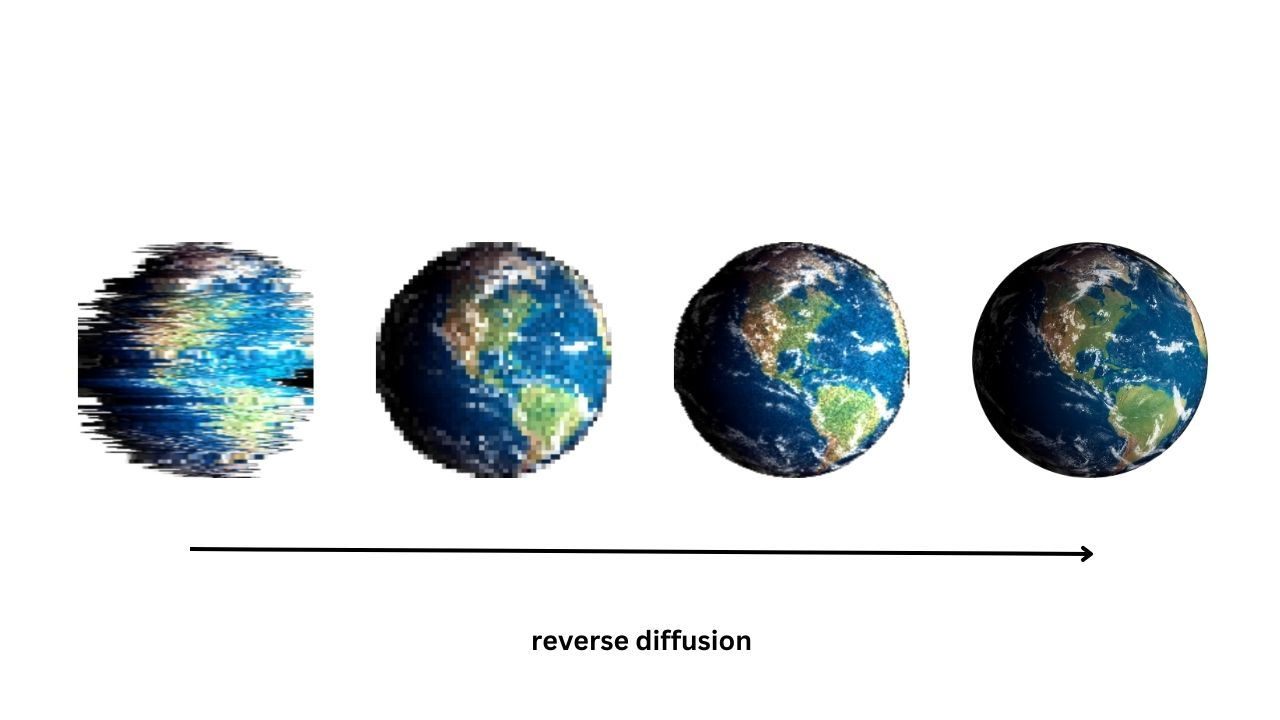
In the context of diffusion models, the reverse process refers to the ability of the diffusion model to take a noisy or degraded image and “clean it up” to create a high-quality image, as shown in the image above. This is done by running the image through the diffusion process in reverse, which removes the added noise.
Data distribution
Diffusion models rely on a large amount of data to generate high-quality images, and the quality of the generated images depends on the diversity and quality of the data distribution. By analyzing the data distribution, the model can learn to generate images that accurately reflect the characteristics of the input data. This is particularly important in generative modeling, where the goal is to create new data that is similar to the original data distribution.
Prompt engineering
Diffusion models need prompts to control their outputs. Your satisfaction with the model’s output will depend on the precision of your prompt. Prompts consist of a frame, subject, style, and optional seed. Experimentation with prompt engineering is necessary to achieve desired results. It is recommended to start with a simple prompt and adjust as needed. For more on this topic, read our prompt engineering article.
Characteristics of diffusion models
So what is it about diffusion models that makes them so viral and better that their predecessors?
Diffusion models are a very powerful tool for image synthesis and reducing noise in machine learning. Such a model has the ability to generate high-quality images, which makes them a promising area of research for future applications in retail and e-commerce, entertainment, social media, AR/VR, marketing, and more.
Diffusion models are different from their predecessors because they use a diffusion process to generate highly realistic images and match the same data point distribution of real images better than GANs. Meaning that the process helps to make the pictures more varied and stable, and less likely to look the same.
Diffusion models can be conditioned on a wide variety of inputs, such as text, bounding boxes, masked images, and lower-resolution images. They can also be used for super-resolution and class-conditional image generation.
Examples of diffusion models
The most recent of all foundation models, and by some the most advanced, diffusion models have quickly become the talk of the town. From copyright discussions to concerns about AI-generated art overtaking human creativity, diffusion models like DALL-E 2 and stable diffusion have made headlines. DALL-E 2 and Stable Diffusion are not the only ones, but they are some of the best AI art generators on the market.
Diffusion model tools like these make it easy for beginners to access the world of image generation, inpainting, and outpainting. Each of the platforms allows new users to test out its features with a free trial run with a certain number of credits.
DALL-E 2
DALL-E 2 is a creation of OpenAI, developed as a large language model to generate images from textual inputs. It has been the star of numerous headlines about AI art generators.
DALL-E 2 enables you to get a unique image generated from a few words of your input. Dall-E 2 provides a simple user interface without many frills, to generate images, inpainting, and outpainting. The model uses a process called text-to-image synthesis, which allows it to be aware of various visual concepts and generate corresponding images with intricate details.
DALL-E 2 has massive potential, especially in industries like advertising and entertainment, where the model can be used to generate personalized art and images. With new research being conducted and new tools being developed by OpenAI, we are yet to see the full extent of DALL-E’s possibilities.
Stable Diffusion

Stable diffusion is an AI model that can generate high-quality images from textual descriptions. It works by taking a starting image and gradually refining it until it matches the given description, with a number of parameters. This process is known as text-to-image synthesis and can be used to create a wide range of images, including realistic photos and abstract art.
Stable Diffusion allows you to control the level of detail and complexity in the generated images by adjusting a number of parameters. This diffusion model has many potential applications, including creating personalized art, generating realistic and cheaper-to-produce images for video games and movies, and even helping scientists in visualizing complex data.

Ways to use diffusion models
From image generation, inpainting, and outpainting to video generation, the possibilities of diffusion models are numerous. These tools can help you restore old photos, add, delete, or replace people and objects from images, or change the image completely with little to no photoshopping skills!
Inpainting
Inpainting is an advanced image editing technique that allows users to modify specific areas of an image by replacing them with new content generated by a diffusion model. This model uses information from the surrounding pixels to ensure that the generated content fits seamlessly into the context of the original image.
Unlike traditional editing tools that simply erase or mask out certain areas of an image, inpainting generates entirely new content to fill in the missing areas. This process works equally well with real-world or computer-generated images and can be used to enhance images in a wide range of applications. For example, you can use inpainting to modify a family portrait from an old wedding (where your plus one was an ex), by replacing certain parts of the image with new content generated by the diffusion model.







Inpainting is also used in the restoration of old photos, where certain parts of the image may have faded or been damaged over time. By applying a mask to the damaged area and using inpainting, a diffusion model can generate new content to fill in the missing parts of the image. This can help to restore the photo to its original quality and make it look as if it was just taken recently.

Outpainting
With outpainting, users can expand their creative possibilities by adding visual elements beyond the original borders of an image, maintaining the same style or even taking the narrative in new directions. It works by starting with a real-world or generated image and extending it until it becomes a larger, coherent scene. For example, with one input image, you can select a region on the outside border, and generate prompts that will create an extended scene that is coherent with the original image.



Outpainting requires a bit more refinement of the prompts in order to generate coherent scenes, but it allows for the creation of larger, more complex images that would have taken a lot longer to create with traditional image editing methods. This takes image generation to a whole other level!
Video Generation
The image diffusion model has been used to generate high-quality images, and now this technology is being extended to video generation. Meta and Google have recently announced AI systems that use diffusion models to generate short video clips based on text prompts. These models use computer vision and score-based generative modeling to create high-quality videos that are approximately five seconds long.
Image Curation
If you’re looking for a collection of generated images and their associated prompts, you might find a diffusion model image curation site like Lexica.art helpful. These sites have millions of images indexed and provide highly curated collections, so there’s a good chance that the image you want already exists and is just a quick search away. Unlike generating images using a diffusion model, searches are low latency and you can get the images almost instantly.
This is ideal for experimenting, exploring prompts, or searching for specific types of images for free. Additionally, these sites can be useful for learning how to use diffusion models, and how to write the prompts that will generate your desired image in one try.
Final Thoughts
Diffusion models have revolutionized the field of generative modeling by providing powerful tools like DALL-E 2 and Stable Diffusion for image synthesis and noise reduction. They are capable of generating very diverse and stable images that are similar but slightly different from the original data distribution, providing a wide range of possible outputs.
These models rely on technical terms like score-based generative modeling, latent space, Gaussian noise, and reverse diffusion process, which enables them to create high-quality images. Furthermore, diffusion models are currently useful in various fields like retail, e-commerce, entertainment, social media, AR/VR, and marketing, and with time we will only witness their possibilities more and more as many businesses utilize them in order to provide personalized content.
As more businesses discover the power of diffusion models to help solve their problems, it is likely that new types of careers will emerge, one of them being “Prompt Engineers.”





