

The Magic Behind Large Language Models
Were you ever curious about how ChatGPT works? And just why is everyone talking about how powerful it can become?
In this act, we lift the veil of confusing terms from the viral ChatGPT and other large language models! You don’t have to be a computer wiz to thoroughly understand them, even Houdini’s stunts seem simple when properly explained.
What are large language models?
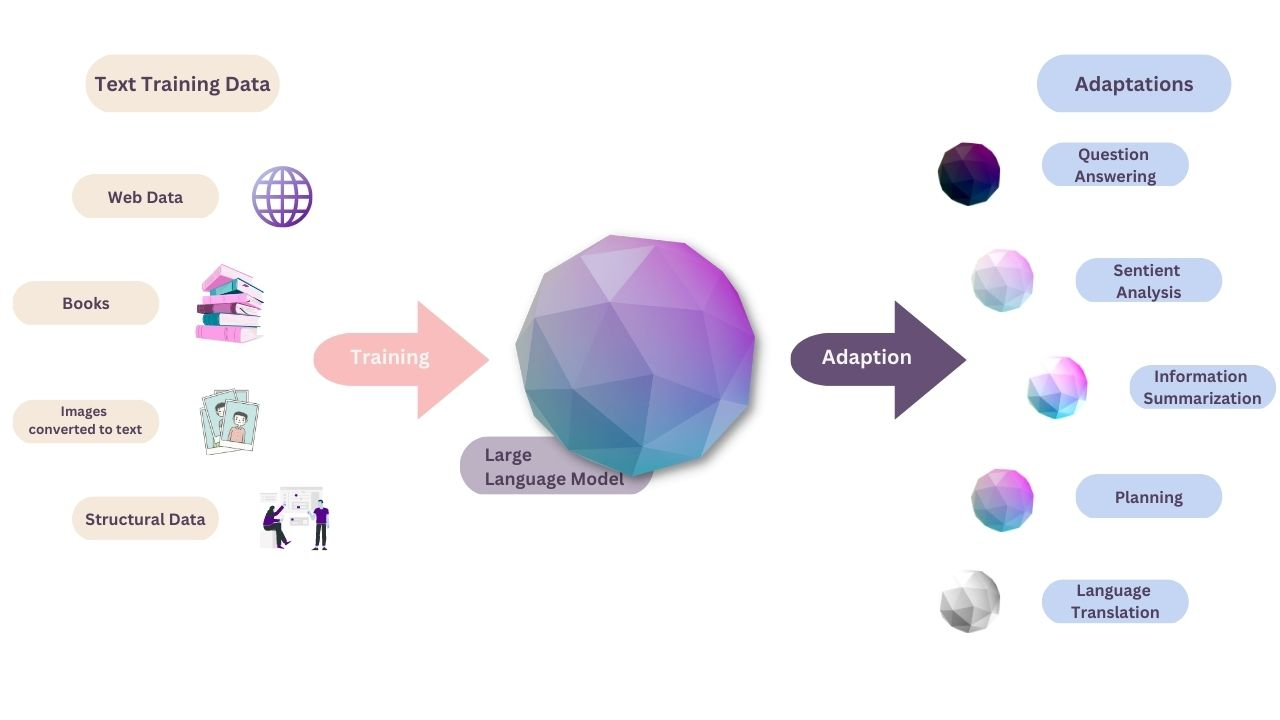
Large language models (LLMs) are advanced artificial intelligence models that are designed to process language on a large scale. They are designed to take a prompt or question (input) and use their learned knowledge to provide an output, such as an answer or translation. They can be used in a variety of ways, including question-answering, text analysis, information, summarization, code generation, planning, and language translation.
Large language models are a type of foundation model. Foundation models are machine learning models that can be customized and adapted to tackle a wide range of other tasks. They are trained on large amounts of data (called training data) in order to give us desired output based on our input. Foundation models are trained in a specific way, where the data that is given to the model is not labeled, meaning the model doesn’t know what it is looking at. This type of training the model is explained in our article about foundation models.
But let’s go back to large language models, and how they fit in the picture. Foundation models are NOT large language models, but large language models ARE a type of foundation model called transformer-based large language models (called transformers for short). They have a specific way they were built, which is called neural network architecture (because it resembles how the neurons connect in the human brain).
AI principles behind large language models
You don’t have to be a computer science enthusiast to understand the principles behind machine learning techniques and how large language models work. Such models are often enclouded in terminology that makes the matter more complex than it needs to be.
Neural networks
As previously mentioned, large language models are built using a special neural network architecture called transformer-based large language models, which resembles the way neurons connect in the human brain. This allows LLMs to predict and process language with incredible accuracy and speed.
Transformer architecture
Large language models are built using a special neural network architecture called transformer-based LLMs, which resembles the way neurons connect in the human brain. This allows language models to have a better understanding of natural language and process language with incredible accuracy and speed.
Self-supervised learning
These types of language models are trained on massive amounts of data (called training data) through unsupervised learning, meaning the model doesn’t know what it’s looking at. This training allows the model to learn how to accurately process language through a technique called self-supervised learning.
Transfer learning
Large language models also use transfer learning, which means they can leverage their learned knowledge from one task to train them to perform another task. For example, a large language model that has been trained to translate English to French can use its learned knowledge to translate English to Spanish.
Characteristics of large language models

Being a subgroup of foundation models, large language models share some of the same characteristics: they are generative in nature, trained with self-supervised learning, and adaptable to other tasks.
LLMs can take different kinds of inputs, but they are primarily trained on text data. Some examples of input include raw text (such as blog posts, news articles, and social media posts), structured data (tables, spreadsheets, or databases, as long as the data is first converted into text), and images (some models have been developed to also work with images by converting the image into a textual description).
Large language models learn from the training data, and can later be used to generate different kinds of text based on our input. They can be used to generate answers to our questions, summarization of our text, or even a weekend getaway plan, hour-by-hour.
Other foundation models are often smaller and less complex than large language models. They are typically trained on a smaller dataset and they number less of the model’s parameters, which limits their capabilities. Large language models, on the other hand, are much more complex and powerful, if only for their hundreds of billions of parameters.
Large language models may exhibit hallucinations (very confident and strange responses by AI that are simply not true or justified by its limited training data), which are emergent behaviors not anticipated or intended during training.
Examples of large language models
Powerful LLMs have become a hot topic in research and development in recent years. They are able to predict the next word in a sentence, understand relationships between words and ideas, search for specific content based on context, and more.
While these models have some limitations and pose technical challenges, they offer exciting possibilities for specific use cases and applications. This is why we are seeing more and more companies launching their own large language models.
ChatGPT, GPT-3, GPT 3.5, and GPT-4
OpenAI has been at the forefront of computer science research, developing state-of-the-art AI models as well as more computationally efficient, smaller models. ChatGPT brought the phrase “large language model” into public discourse and popularity, but models like these existed years before.
Recent research and progress are unlocking new possibilities of what can be achieved using large language models. Their focus on pre-training larger models has led researchers to breakthroughs in natural language processing, allowing for next-word prediction and context-sensitive responses.
GPT-3
GPT-3 is a large language model with a transformer architecture consisting of multiple hidden layers, enabling it to very effectively process text inputs and produce high-quality outputs. It is designed to enable it to respond to text-based inputs, such as prompts or questions, with human-like outputs.
The model’s parameter count is impressive, making it one of the largest to date (ranging from 175 billion to 300 billion parameters, depending on the model). This makes such models very resource-intensive to train and fine-tune, and also requires great computational efficiency.
GPT-3 can be fine-tuned (adapting the model to new tasks or domains) with new data for specific use cases or challenges and can also be pre-trained on large amounts of data to improve its ability to comprehend and generate text. The model has shown great promise in a variety of language tasks, including text summarization, understanding context, and generating responses.
ChatGPT
ChatGPT is an interactive chatbot that uses pre-trained language models, including GPT-3, to generate human-sounding responses to user inputs. The model consists of multiple hidden layers that are responsible for processing and generating model outputs. With its ability to understand and respond to new data in context, ChatGPT can be fine-tuned for specific use cases or trained on new data for text summarization, language tasks, and other research purposes.
GPT 3.5
GPT-3.5 is an AI large language model that was developed by OpenAI as a test run and a new and improved version of their previous model. It is built using the same architecture as GPT-3 and used to identify and fix any bugs, as well as to improve their theoretical foundations. It showcased impressive performance as it is able to generate human-sounding responses to various prompts.
GPT-4
OpenAI’s most advanced system, GPT-4, generates responses that are both safer and more useful. OpenAI’s most recent creation is a large multimodal model that can accept both image and text inputs and emit text outputs. Although it is less capable than humans in real-world scenarios, it exhibits human-level performance on various professional and academic benchmarks, such as passing a simulated bar exam with a score around the top 10% of test takers.
BERT
Bidirectional Encoder Representations from Transformers (BERT) is a family of language models launched in 2018 by Google. BERT is pre-trained on two tasks: language modeling and next-sentence prediction, allowing it to learn latent representations of words and sentences in context. It was trained on a large amount of text from books and Wikipedia to learn how words relate to each other in sentences. BERT is really good at understanding natural language and has been used for Google search queries in many languages. Google continues improving its LLMs and plans to roll out a google search companion AI for all to use.
BLOOM
BLOOM is a large language model that has been developed by over 1000 researchers from 70+ countries and 250+ institutions. With 176 billion parameters, BLOOM can generate text in 46 natural languages and 13 programming languages. This makes it the first language model to have over 100 billion parameters for many languages.
BLOOM has been created to change the way large language models are used by making it easier for researchers, individuals, and institutions to access and study them. Anyone who agrees to the terms of the Responsible AI License can use and build upon BLOOM. BLOOM’s capabilities will continue to improve as more experiments are conducted and new languages are added.
Ways to use large language models
LLMs are powerful tools that can be used in a vast variety of functions and applications, including the ones mentioned below. These applications are made possible due to LLMs’ ability to process language with great accuracy and speed, as well as their capacity to handle a wide range of tasks.
Question Answering
One of the most popular applications of LLMs is question answering, mostly due to the popularity of ChatGPT. The models can be trained to read and understand a large amount of text, and then provide answers (outputs) to questions based on that text. This is done by inputting the question and providing the LLM with contexts, such as a passage of text or a webpage. The LLM then uses its learned knowledge to provide an answer to the question.
Sentiment Analysis
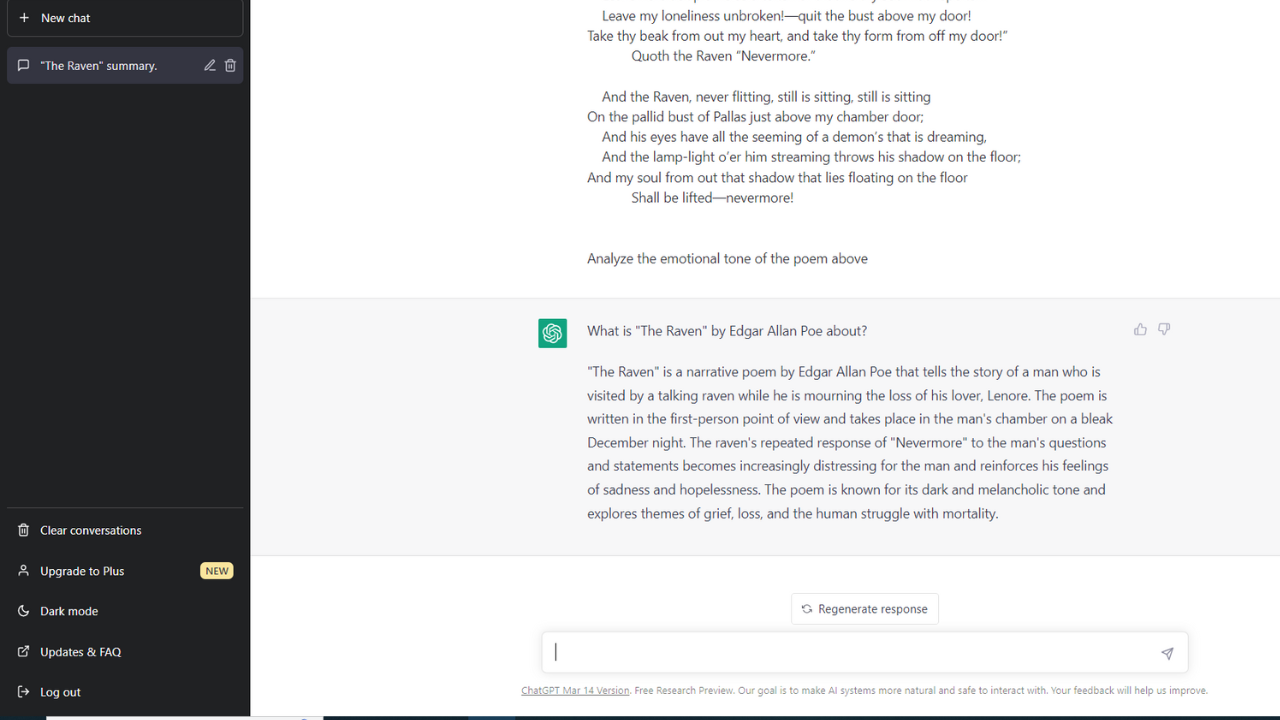
Sentiment analysis involves analyzing the emotional tone of a piece of text. This is useful for businesses and organizations that want to understand how their customers or clients feel about their products or services or to make sure the text they are about to put in from of clients has the right tone.
LLMs can analyze large amounts of text and provide insights into the sentiment of that text, allowing organizations to make data-driven decisions.
Information Summarization
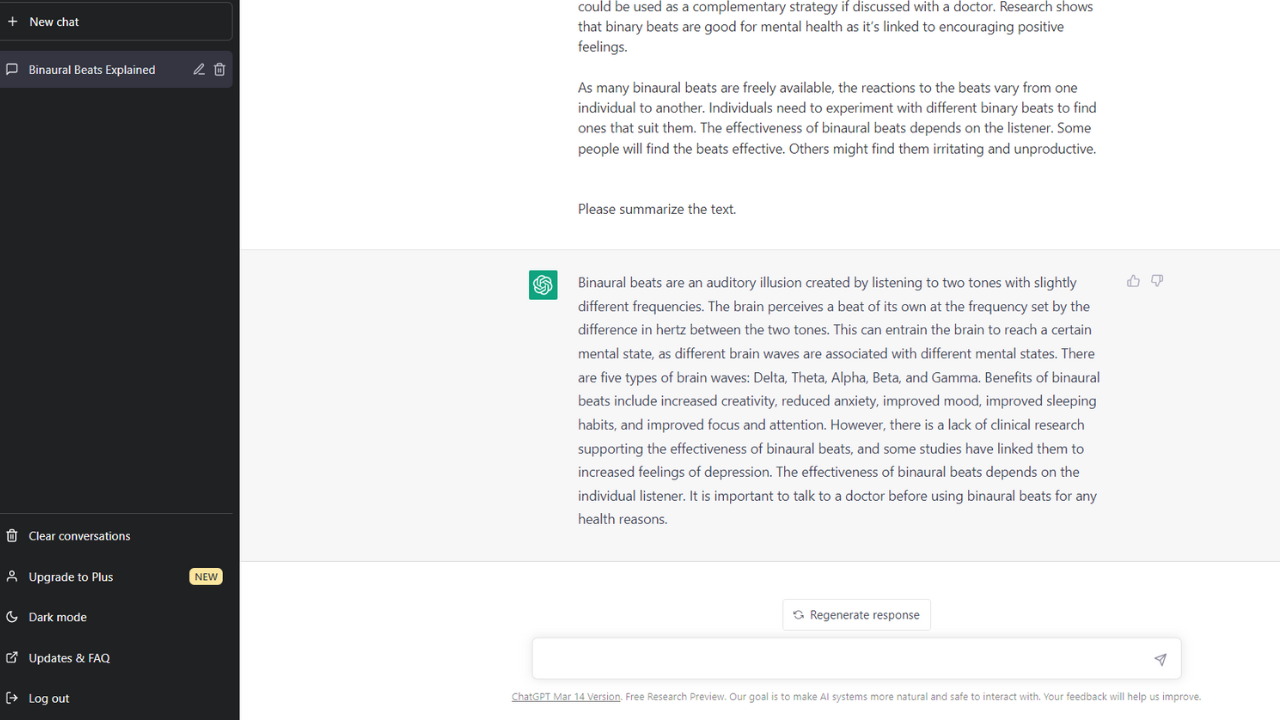
Information summarization involves taking a large amount of text and summarizing it into a shorter, more concise version. This is useful in situations where a large amount of information needs to be conveyed quickly, such as in news articles or reports. LLMs can analyze the text and provide a summary that captures the main points of the original text. There are now a number of AI summarization tools on the market.
Planning
Planning with LLMs involves generating plans based on a set of goals and constraints. This is useful in a variety of applications, such as scheduling, logistics, and resource allocation. LLMs can analyze the goals and constraints and generate plans that meet those requirements.
Language Translation
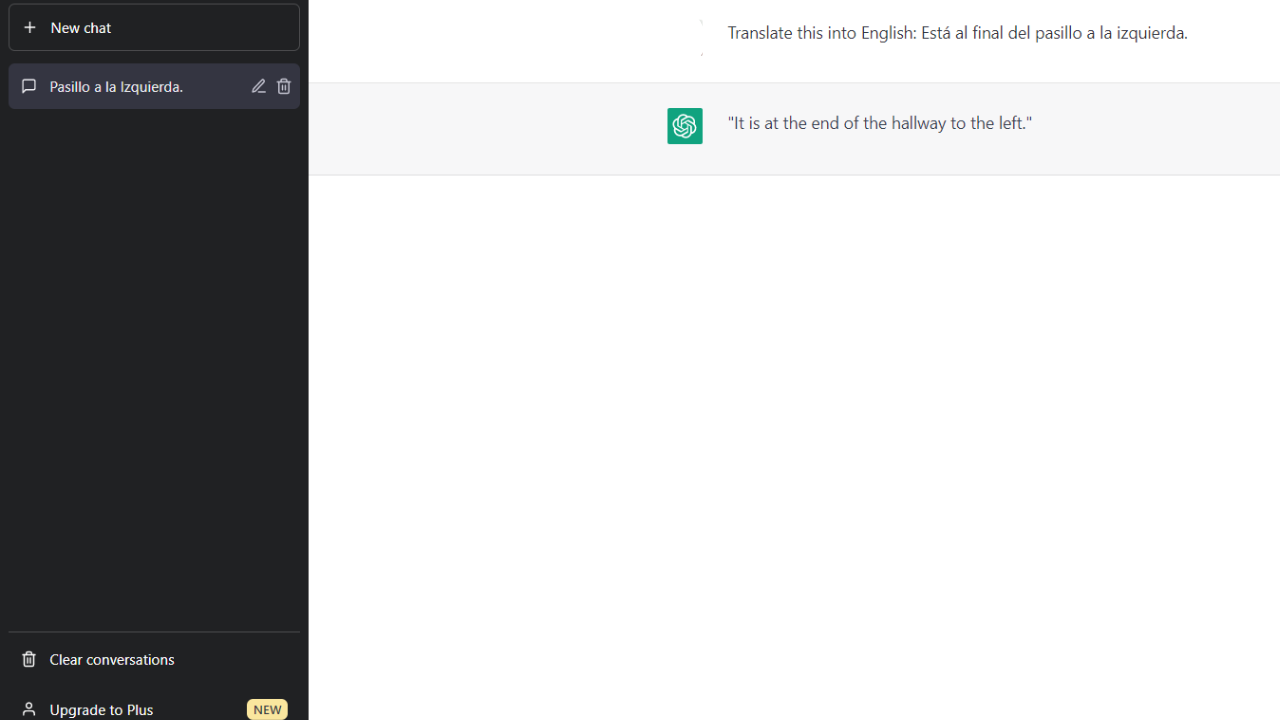
Language translation by large language models can be useful for individuals and organizations that need to communicate across the world and struggle with language barriers. From business meeting notes to instant video caption translation, LLMs can analyze the text and provide a translation that captures the meaning of the original text.
Final thoughts
Large language models are relatively new to the family of foundation models, and yet they have been the ones to bring AI and AI usage to the mainstream. The virality of ChatGPT started the discourse about the implementation of artificial intelligence into our lives and work, leaving many worried about being left behind.
Now, the tech giants are racing to develop, enhance and push out their own models and integrate them into the products we use daily. The benefits could be great: unprecedented advancements in healthcare, education, science, and technology. But, we are yet to see just how much models like these, along with the inevitable backlash, regulations, research, and breakthroughs are going to impact our society.

![11 Best AI UX Tools of 2024 [By Category]](https://renaissancerachel.com/wp-content/uploads/2026/06/best-ai-ux-tools-clean-768x402.jpg)



